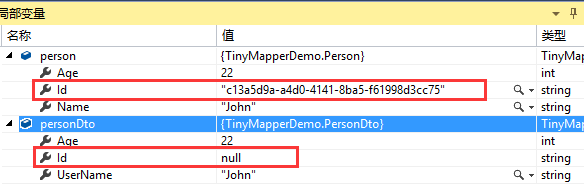
/// <summary>最简单的2个类型之间的映射</summary> static void Test1() { TinyMapper.Bind<Person,PersonDto>(); //实例化一个Person对象 var person = new Person { Id = Guid.NewGuid().ToString(), Name = "John", Age = 22 }; //映射 var personDto = TinyMapper.Map<PersonDto>(person); }
运行看看结果:
3.Tiny Mapper 指定配置使用
有时候对象的字段名称并不一样,而且可能要忽略某些字段,这个时候就要使用更加灵活的配置了。
看例子,为了演示,我们特意修改2个类型的字段名称不一样.如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
public class Person { public String Id { get; set; } public String Name { get; set; } public Int32 Age { get; set; } }
public class PersonDto { public String Id { get; set; } //注意这里的字段名称:UserName public String UserName { get; set; } public Int32 Age { get; set; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
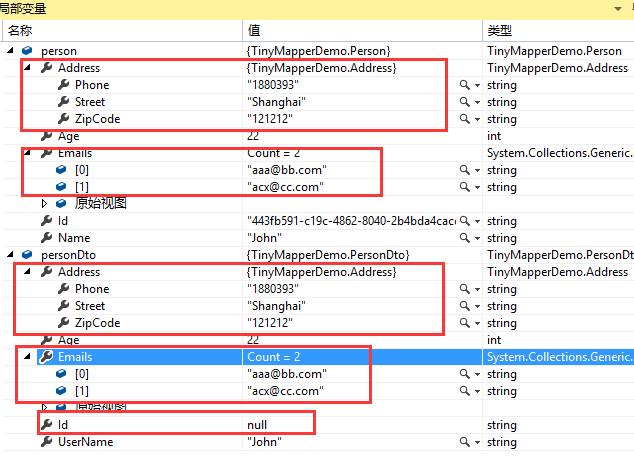
/// <summary>使用配置项指定和忽略字段</summary> static void Test2() { TinyMapper.Bind<Person, PersonDto>(config => { config.Ignore(x => x.Id);//忽略ID字段 config.Bind(x => x.Name, y => y.UserName);//将源类型和目标类型的字段对应绑定起来 config.Bind(x => x.Age, y => y.Age);//将源类型和目标类型的字段对应绑定起来 }); var person = new Person { Id = Guid.NewGuid().ToString(), Name = "John", Age = 22 }; var personDto = TinyMapper.Map<PersonDto>(person); }
public class Person { public String Id { get; set; } public String Name { get; set; } public Int32 Age { get; set; } public Address Address { get; set; } public List<String> Emails { get; set; } }
public class PersonDto { public String Id { get; set; } public String UserName { get; set; } public Int32 Age { get; set; } public Address Address { get; set; } public List<String> Emails { get; set; } }
public sealed class Address { public string Phone { get; set; } public string Street { get; set; } public string ZipCode { get; set; } }
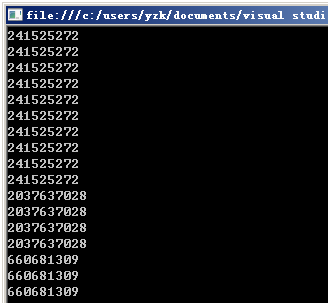
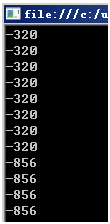
for(int i=0;i<100;i++) { Random rand = new Random(); System.out.println(rand.nextInt()); }
因为低版本Java中Rand类的无参构造函数的实现同样是用当前时间做种子:
public Random() { this(System.currentTimeMillis()); }
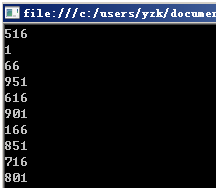
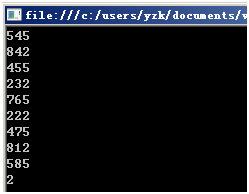
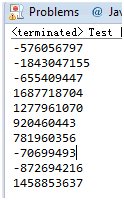
但是在高版本的Java中,比如Java1.8中,上面的”错误”代码执行却是没问题的:
为什么呢?我们来看一下这个Random无参构造函数的实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13
public Random() { this(seedUniquifier() ^ System.nanoTime()); } private static long seedUniquifier() { for (;;) { long current = seedUniquifier.get(); long next = current * 181783497276652981L; if (seedUniquifier.compareAndSet(current, next)) return next; } } privatestaticfinal AtomicLong seedUniquifier = new AtomicLong(8682522807148012L);
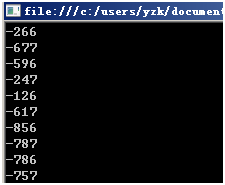
因为每次生成Guid的值都不样,网上有的文章说可以创建一个Guid计算它的HashCode或者MD5值的方式来做种子: new Random(Guid.NewGuid().GetHashCode()) 。但是我认为Guid的生成算法是确定的,在条件充足的情况下也是可以预测的,这样生成的随机数也有可预测的可能性。当然只是我的猜测,没经过理论的证明。