前言:xml的操作方式有多种,但要论使用频繁程度,博主用得最多的还是Linq to xml的方式,觉得它使用起来很方便,就用那么几个方法就能完成简单xml的读写。之前做的一个项目有一个很变态的需求:C#项目调用不知道是什么语言写的一个WebService,然后添加服务引用总是失败,通过代理的方式动态调用也总是报错,最后没办法,通过发送原始的WebRequest请求直接得到对方返回的一个xml文件。注意过webservice的wsdl文件的朋友应该知道这个是系统生成的xml文件,有点复杂,研究了半天终于能正常读写了。今天在这里和大家分享下。
var strPath = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, @"data\test.xml"); XDocument adList = XDocument.Load(strPath); var ad = from a in adList.Descendants("BizADsList").Elements("adData") select new { image = a.Attribute("image").Value, link = a.Attribute("link").Value, title = a.Attribute("title").Value }; string s = ""; foreach (var a in ad) s += a.image;
CREATE USER 'dog'@'localhost' IDENTIFIED BY '123456'; CREATE USER 'pig'@'192.168.1.101_' IDENDIFIED BY '123456'; CREATE USER 'pig'@'%' IDENTIFIED BY '123456'; CREATE USER 'pig'@'%' IDENTIFIED BY ''; CREATE USER 'pig'@'%';
二. 授权:
命令:
1
GRANT privileges ON databasename.tablename TO 'username'@'host'
说明:
privileges:用户的操作权限,如 SELECT , INSERT , UPDATE 等,如果要授予所的权限则使用 ALL
GRANT SELECT, INSERT ON test.user TO 'pig'@'%'; GRANT ALL ON *.* TO 'pig'@'%';
注意:
用以上命令授权的用户不能给其它用户授权,如果想让该用户可以授权,用以下命令:
1
GRANT privileges ON databasename.tablename TO 'username'@'host' WITH GRANT OPTION;
三.设置与更改用户密码
命令:
1
SET PASSWORD FOR 'username'@'host' = PASSWORD('newpassword');
如果是当前登陆用户用:
1
SET PASSWORD = PASSWORD("newpassword");
例子:
1
SET PASSWORD FOR 'pig'@'%' = PASSWORD("123456");
四. 撤销用户权限
命令:
1
REVOKE privilege ON databasename.tablename FROM 'username'@'host';
说明:
privilege, databasename, tablename:同授权部分
例子:
1
REVOKE SELECT ON *.* FROM 'pig'@'%';
注意:
假如你在给用户 'pig'@'%' 授权的时候是这样的(或类似的): GRANT SELECT ON test.user TO 'pig'@'%' ,则在使用 REVOKE SELECT ON *.* FROM 'pig'@'%'; 命令并不能撤销该用户对test数据库中user表的 SELECT 操作。相反,如果授权使用的是 GRANT SELECT ON *.* TO 'pig'@'%'; 则 REVOKE SELECT ON test.user FROM 'pig'@'%'; 命令也不能撤销该用户对test数据库中user表的 Select 权限。
具体信息可以用命令 SHOW GRANTS FOR 'pig'@'%'; 查看。
五.删除用户
命令:
1
DROP USER 'username'@'host';
六.刷新
1 2 3
支持远程连接: ALTER user 'root'@'%' IDENTIFIED WITH mysql_native_password BY '***'; FLUSH PRIVILEGES;
_submitForm(recaptchaId, value) { for (const i in this.validateForm.controls) { if (this.validateForm.controls.hasOwnProperty(i)) { this.validateForm.controls[i].markAsDirty(); } }
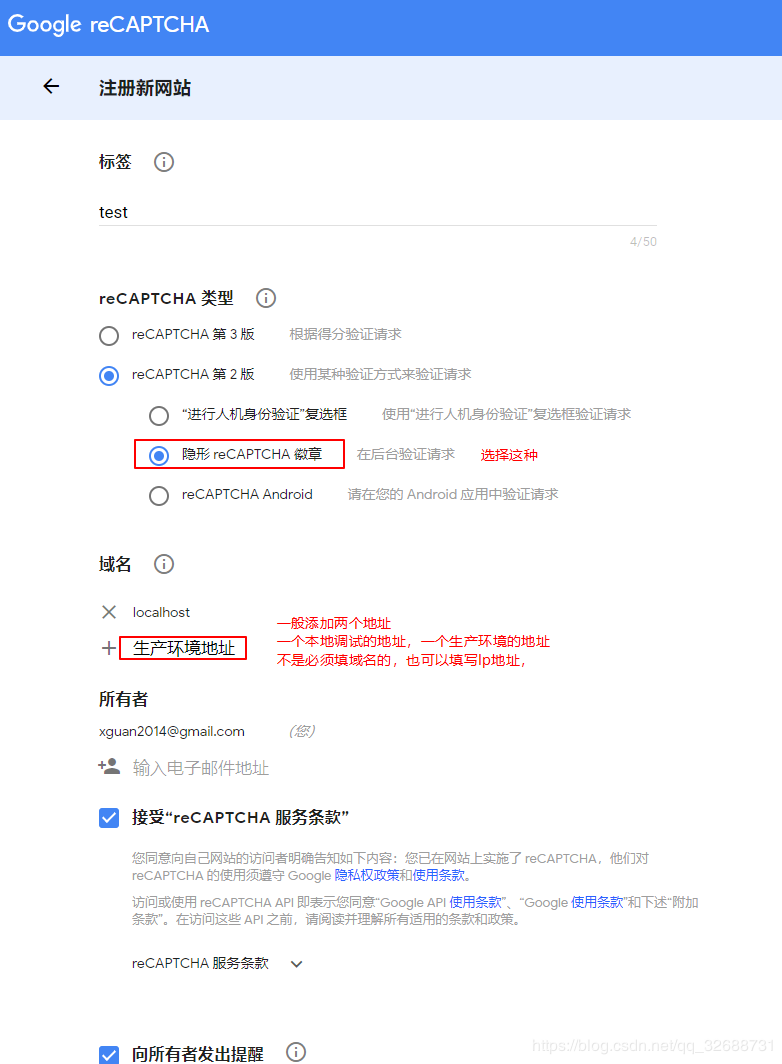
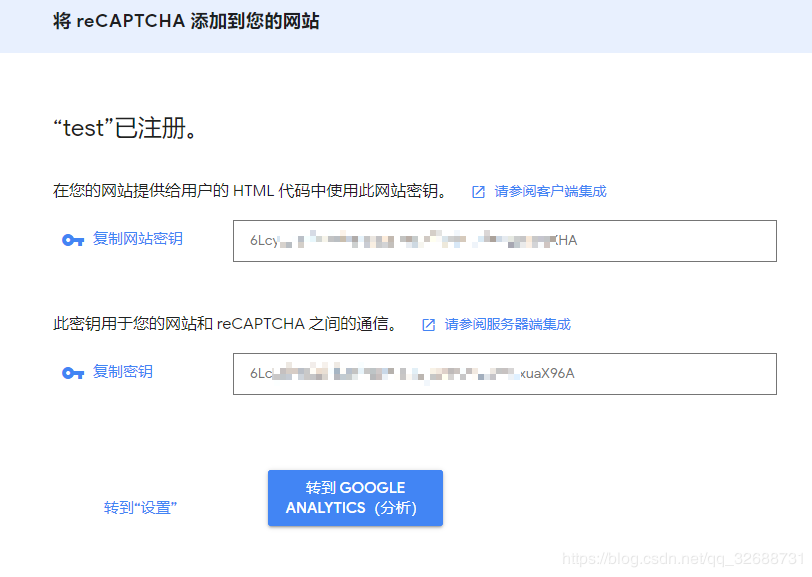
var values = new Dictionary<string, string> { { "secret", secretKey }, { "response",recaptchaToken } }; var content = new FormUrlEncodedContent(values); HttpClient httpClient = new HttpClient();
var response = await httpClient.PostAsync(baseUrl, content); var responseString = await response.Content.ReadAsStringAsync();
var obj = JObject.Parse(responseString); var status = (bool)obj.SelectToken("success"); return status; }