List<string> list = new List<string>();// 初始化一个空的列表 List<string> list1 = new List<string>{"12", "2"};//初始化一个包含两个元素的列表 list1 = new List<string>(100);//初始化一个空的列表,并指定list的初始容量为100 list = new List<string>(list1);// 使用一个List/Array 初始化一个列表
List<string> list = new List<string>();// 初始化一个空的列表 list.Add("12");//list = {"12"} List<string> list1 = new List<string>{"14", "2"}; list.AddRange(list1);// list = {"12","14","2"}
1 2 3 4 5 6 7 8 9 10 11 12
4. `Insert(int index, T item)`或`InsertRange(int index,IEnumerable<T> items)` 插入
Set<T> set = new HashSet<T>();// = new SortSet<T>(); 初始化一个空的集合 //使用一个集合对象初始化 Set<T> set1 = new HashSet<T>(IEnumerable<T> items);// = new SortSet<T>(IEnumerable<T> items); Set<T> set2 = new HashSet<T>(){T t1, T t2, T t3};// 与上一种一样
using System; using System.Collections; publicclassSamplesSortedList {
publicstaticvoidMain() {
// Creates and initializes a new SortedList. SortedList mySL = new SortedList(); mySL.Add("Third", "!"); mySL.Add("Second", "World"); mySL.Add("First", "Hello");
// Displays the properties and values of the SortedList. Console.WriteLine( "mySL" ); Console.WriteLine( " Count: {0}", mySL.Count ); Console.WriteLine( " Capacity: {0}", mySL.Capacity ); Console.WriteLine( " Keys and Values:" ); PrintKeysAndValues( mySL ); }
publicstaticvoidPrintKeysAndValues( SortedList myList ) { Console.WriteLine( "t-KEY-t-VALUE-" ); for ( int i = 0; i < myList.Count; i++ ) { Console.WriteLine( "t{0}:t{1}", myList.GetKey(i), myList.GetByIndex(i) ); } Console.WriteLine(); } }
classExample { publicstaticvoidMain() { // Create a new hash table. // Hashtable openWith = new Hashtable();
// Add some elements to the hash table. There are no // duplicate keys, but some of the values are duplicates. openWith.Add("txt", "notepad.exe"); openWith.Add("bmp", "paint.exe"); openWith.Add("dib", "paint.exe"); openWith.Add("rtf", "wordpad.exe");
// The Add method throws an exception if the new key is // already in the hash table. try { openWith.Add("txt", "winword.exe"); } catch { Console.WriteLine("An element with Key = "txt" already exists."); }
// The Item property is the default property, so you // can omit its name when accessing elements. Console.WriteLine("For key = "rtf", value = {0}.", openWith["rtf"]);
// The default Item property can be used to change the value // associated with a key. openWith["rtf"] = "winword.exe"; Console.WriteLine("For key = "rtf", value = {0}.", openWith["rtf"]);
// If a key does not exist, setting the default Item property // for that key adds a new key/value pair. openWith["doc"] = "winword.exe";
// ContainsKey can be used to test keys before inserting // them. if (!openWith.ContainsKey("ht")) { openWith.Add("ht", "hypertrm.exe"); Console.WriteLine("Value added for key = "ht": {0}", openWith["ht"]); }
// When you use foreach to enumerate hash table elements, // the elements are retrieved as KeyValuePair objects. Console.WriteLine(); foreach( DictionaryEntry de in openWith ) { Console.WriteLine("Key = {0}, Value = {1}", de.Key, de.Value); }
// To get the values alone, use the Values property. ICollection valueColl = openWith.Values;
// The elements of the ValueCollection are strongly typed // with the type that was specified for hash table values. Console.WriteLine(); foreach( string s in valueColl ) { Console.WriteLine("Value = {0}", s); }
// To get the keys alone, use the Keys property. ICollection keyColl = openWith.Keys;
// The elements of the KeyCollection are strongly typed // with the type that was specified for hash table keys. Console.WriteLine(); foreach( string s in keyColl ) { Console.WriteLine("Key = {0}", s); }
// Use the Remove method to remove a key/value pair. Console.WriteLine("nRemove("doc")"); openWith.Remove("doc");
if (!openWith.ContainsKey("doc")) { Console.WriteLine("Key "doc" is not found."); } } }
/* This code example produces the following output: An element with Key = "txt" already exists. For key = "rtf", value = wordpad.exe. For key = "rtf", value = winword.exe. Value added for key = "ht": hypertrm.exe Key = dib, Value = paint.exe Key = txt, Value = notepad.exe Key = ht, Value = hypertrm.exe Key = bmp, Value = paint.exe Key = rtf, Value = winword.exe Key = doc, Value = winword.exe Value = paint.exe Value = notepad.exe Value = hypertrm.exe Value = paint.exe Value = winword.exe Value = winword.exe Key = dib Key = txt Key = ht Key = bmp Key = rtf Key = doc Remove("doc") Key "doc" is not found. */
using System; using System.Text; using System.Collections.Generic;
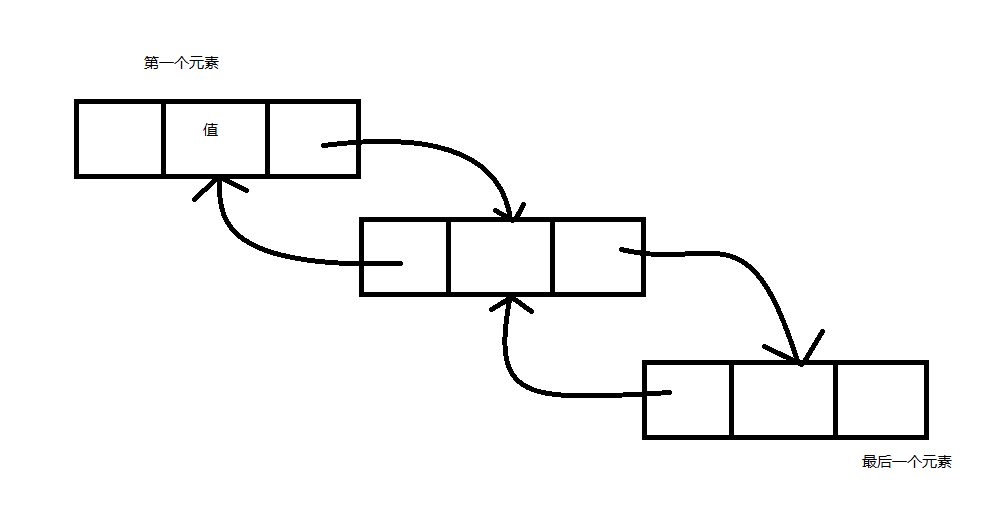
publicclassExample { publicstaticvoidMain() { // Create the link list. string[] words = { "the", "fox", "jumps", "over", "the", "dog" }; LinkedList<string> sentence = new LinkedList<string>(words); Display(sentence, "The linked list values:"); Console.WriteLine("sentence.Contains("jumps") = {0}", sentence.Contains("jumps"));
// Add the word 'today' to the beginning of the linked list. sentence.AddFirst("today"); Display(sentence, "Test 1: Add 'today' to beginning of the list:");
// Move the first node to be the last node. LinkedListNode<string> mark1 = sentence.First; sentence.RemoveFirst(); sentence.AddLast(mark1); Display(sentence, "Test 2: Move first node to be last node:");
// Change the last node to 'yesterday'. sentence.RemoveLast(); sentence.AddLast("yesterday"); Display(sentence, "Test 3: Change the last node to 'yesterday':");
// Move the last node to be the first node. mark1 = sentence.Last; sentence.RemoveLast(); sentence.AddFirst(mark1); Display(sentence, "Test 4: Move last node to be first node:");
// Indicate the last occurence of 'the'. sentence.RemoveFirst(); LinkedListNode<string> current = sentence.FindLast("the"); IndicateNode(current, "Test 5: Indicate last occurence of 'the':");
// Add 'lazy' and 'old' after 'the' (the LinkedListNode named current). sentence.AddAfter(current, "old"); sentence.AddAfter(current, "lazy"); IndicateNode(current, "Test 6: Add 'lazy' and 'old' after 'the':");
// Indicate 'fox' node. current = sentence.Find("fox"); IndicateNode(current, "Test 7: Indicate the 'fox' node:");
// Add 'quick' and 'brown' before 'fox': sentence.AddBefore(current, "quick"); sentence.AddBefore(current, "brown"); IndicateNode(current, "Test 8: Add 'quick' and 'brown' before 'fox':");
// Keep a reference to the current node, 'fox', // and to the previous node in the list. Indicate the 'dog' node. mark1 = current; LinkedListNode<string> mark2 = current.Previous; current = sentence.Find("dog"); IndicateNode(current, "Test 9: Indicate the 'dog' node:");
// The AddBefore method throws an InvalidOperationException // if you try to add a node that already belongs to a list. Console.WriteLine("Test 10: Throw exception by adding node (fox) already in the list:"); try { sentence.AddBefore(current, mark1); } catch (InvalidOperationException ex) { Console.WriteLine("Exception message: {0}", ex.Message); } Console.WriteLine();
// Remove the node referred to by mark1, and then add it // before the node referred to by current. // Indicate the node referred to by current. sentence.Remove(mark1); sentence.AddBefore(current, mark1); IndicateNode(current, "Test 11: Move a referenced node (fox) before the current node (dog):");
// Remove the node referred to by current. sentence.Remove(current); IndicateNode(current, "Test 12: Remove current node (dog) and attempt to indicate it:");
// Add the node after the node referred to by mark2. sentence.AddAfter(mark2, current); IndicateNode(current, "Test 13: Add node removed in test 11 after a referenced node (brown):");
// The Remove method finds and removes the // first node that that has the specified value. sentence.Remove("old"); Display(sentence, "Test 14: Remove node that has the value 'old':");
// When the linked list is cast to ICollection(Of String), // the Add method adds a node to the end of the list. sentence.RemoveLast(); ICollection<string> icoll = sentence; icoll.Add("rhinoceros"); Display(sentence, "Test 15: Remove last node, cast to ICollection, and add 'rhinoceros':");
Console.WriteLine("Test 16: Copy the list to an array:"); // Create an array with the same number of // elements as the inked list. string[] sArray = newstring[sentence.Count]; sentence.CopyTo(sArray, 0);
foreach (string s in sArray) { Console.WriteLine(s); }
privatestaticvoidDisplay(LinkedList<string> words, string test) { Console.WriteLine(test); foreach (string word in words) { Console.Write(word + " "); } Console.WriteLine(); Console.WriteLine(); }
privatestaticvoidIndicateNode(LinkedListNode<string> node, string test) { Console.WriteLine(test); if (node.List == null) { Console.WriteLine("Node '{0}' is not in the list.n", node.Value); return; }
StringBuilder result = new StringBuilder("(" + node.Value + ")"); LinkedListNode<string> nodeP = node.Previous;